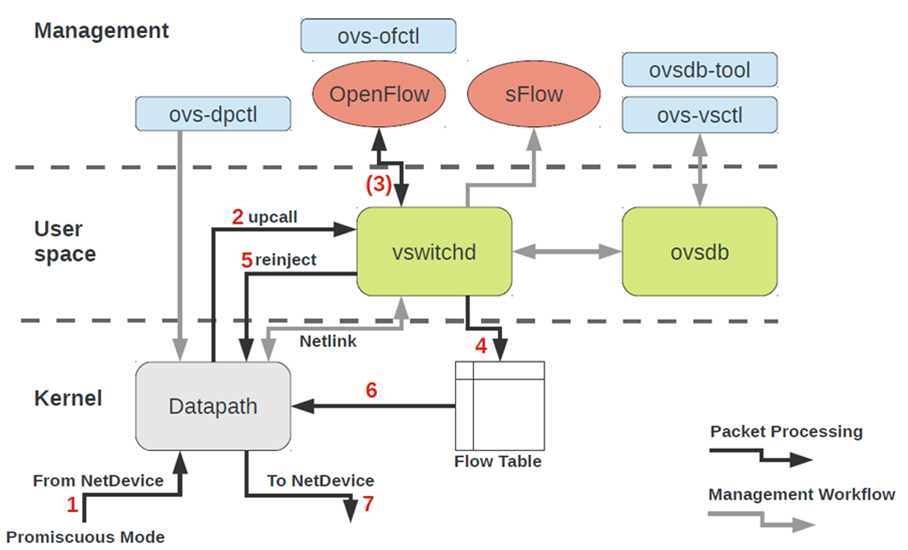
OVS processes packets in datapaths. All datapaths implement a common interface hiding the implementation details of low-level packet processing from the layers above.
The two most commonly used datapath implementations are netdev and netlink. They are named after the mechanism used for integrating with the operating system. The netlink datapath is Linux-specific and uses a special kernel module. The netdev datapath is implemented in userspace.
Datapaths are optimized for high-performance packet processing and they completely handle most of the packets that come through them. Consequently, the forwarding tables in the datapaths are not equivalent to the OpenFlow forwarding tables and a translation mechanism between the two forwarding table formats is present. The translation is performed lazily. When a packet does not match any rule in the datapath forwarding table, an upcall is made and the packet is passed out of the datapath into the upper layers of ovs-vswitchd. ovs-vswitchd performs a full lookup through the OpenFlow forwarding tables and generates a new datapath flow rule which gets inserted into the datapath together with the packet itself.
We use the name fast path to refer to datapath-only packet processing. If the packet misses all datapath flow rules and generates an upcall, we say that it took the slow path.
The netdev datapath
The netdev datapath is a multiplatform datapath implementation entirely in user space. All major operating systems are currently supported.
The netdev datapath supports various configurations according to the system it is running on. The most basic deployment is rather slow as all packets have to cross the userspace boundary twice. However, the datapath can be configured with several types of accelerators significantly lowering the packet processing cost. The datapath can be accelerated using DPDK, AF_XDP sockets or offloaded to hardware using TC.
This article does not focus on the netdev datapath any further.
The netlink datapath
The netlink datapath is Linux-specific. It resides partially in a kernel module and partially in user space. The kernel module does most of the packet processing. The userspace communicates with the kernel over a netlink socket, hence the name. Only the slow path passes data from the kernel space to the user space.
From now on, we will focus on the netlink datapath as it is the most commonly deployed datapath in Kubernetes clusters.
Interactions between the fast path and the slow path
Packets always start their journey in the kernel. They enter the openvswitch module where they are checked against a set of flow rules stored in the flow table (OVS's forwarding table). If a flow rule matches the packet, its actions are executed. Otherwise, the packet is sent to the user space.
def process_packet_in_kernel(packet): for flow_rule in flow_table: if flow_rule criteria match the packet: execute the flow_rule actions return make an upcall to the user space
The slow path gets involved when the fast path fails (no flow rule match) or when the action in the flow rule explicitly asks for it. The packet is sent to the user space via a netlink socket in an upcall. ovs-vswitchd receives the packet, processes it according to the OpenFlow rules and reinjects it back into the kernel. Additionally, a new flow rule might be generated and installed into the kernel to speed up the future processing of similar packets.
The packets in the fast path are not buffered and they are processed immediately. The slow-path buffers packets when they are passed from kernel to user space, introducing additional latency.
The fast-path
The data structures
The flow table (struct flow_table) is an in-kernel data structure, which stores flows rules (struct sw_flow) and allows for fast matching with individual packets. Similar to OpenFlow flow rules, every datapath flow contains a list of actions (struct sw_flow_actions), statistics (struct sw_flow_stats), a flow key (struct sw_flow_key) and a flow mask (struct sw_flow_mask).
The flow key and the flow mask are the matching criteria. The combination of both of these enables fast matching with the possibility of wildcards. The key is a complex structure with parsed-out packet header values. It can be created from any packet with the function key_extract(). The mask specifies which bits are significant when comparing two keys.
def equals(key1, key2, mask) -> bool: return (key1 & mask) == (key2 & mask)
The matching algorithm
When the kernel processes a packet, it creates the packet's corresponding flow key and looks for matching flows in the flow table. The packet can match any number of flows, but only the first matching rule is always used. The userspace component is responsible for preventing overlapping conflicting flow rules.
The flow table stores the flows in a hash table. The lookup key is the masked sw_flow_key. Therefore, to find a flow for a packet, the kernel has to try several masks. The lookup procedure could look like this:
def lookup(flow_table, key): for mask in flow_table.mask_array: masked_key = apply mask to key if masked_key in flow_table.flows: return flow_table.flows[masked_key] return None
The real implementation (ovs_flow_tbl_lookup_stats) is in principle similar, but more optimized:
- The kernel keeps mask usage statistics and the
mask_arrayis kept sorted with the most used masks first (ovs_flow_masks_rebalance()). This happens periodically based on a time interval. - There is already a
sk_buff(a kernel structure wrapping all packets) hash based on source/destination addresses and ports. The lookup procedure makes use of the hash by having a fixed size (256) hash table storing references to their masks. The cached masks are then tried first. If there is no match, a standard lookup over all masks follows and the cache entry is replaced with a new flow. This helps with burst performance.
The actions
The actions in a flow rule are similar to actions in OpenFlow. They are described in the manpages ovs-actions(7).
Special attention should be given to the recirculation action, which corresponds to the resubmit OpenFlow action. This action resubmits the packet to the datapath again, updating its flow key's recirc_id to a new value. This effectively simulates having multiple flow tables in the datapath with only a single physical table.
The slow-path
The user space process (ovs-vswitchd) communicates with the kernel over a netlink socket. When a packet leaves the
fast-path, it is temporarily buffered in a queue (ovs_dp_upcall()) when crossing the kernel boundary.
ovs-vswitchd reads packets from the kernel in several handler threads. The datapath interface defines a recv() function for receiving a single packet from the kernel. The netlink datapath implements it with the dpif_netlink_recv() function.
Higher up, the recv() datapath interface function is used in a generic dpif_recv() function which also provides an useful tracepoint for measurements. Even higher up the abstraction stack, the recv_upcalls() function in the file ofproto-dpif-upcall.c reads packets in batches, which are then processed by handle_upcalls(). The handle_upcalls() function essentially transforms the list of packets into a list of operations that should be executed on the datapath. This includes adding new flows to the datapath as well as simply sending packets where they belong.
Additional ovs-vswitchd tasks
Parallel with upcall processing in the handler threads, OVS also runs several maintenance tasks:
- A balancing task makes sure that when the system is under stress, the most frequently used flow rules are in the kernel.
- The revalidator threads periodically dump statistics from the kernel and remove old unused flows. The number of revalidator threads scales with the number of available cores on the system.